Target confusability competition model (TCC) primer
We have recently proposed a new way of conceiving of visual memory, combining psychophysical scaling of similarity with signal detection theory (see Schurgin, Wixted and Brady, 2020, Nature Human Behaviour; PDF). Both of these are extremely well-established concepts, but together they result in a simple model of both visual working memory and visual long-term memory that allows us to make novel predictions and explain memory performance in a very straightforward way.
All models like this are best explained visually — and with animations. Even signal detection theory, which many people have some familiarity with, is a more profound model than many realize — signal detection theory is much more than just a "measurement model" for correcting for response bias. It's really an entire framework for conceiving of memory and decision making under noise. Thus, we've made this informal primer to help people understand the model we are proposing. If you'd rather see a short talk, you could also watch Tim Brady's 12 minute talk from Neuromatch.
Signal detection in a 2-alternative forced choice memory test
To begin, consider the simplest case of memory. Imagine we've asked you to remember this color: . Then, after some amount of delay, we ask you to say which of two colors you've seen in a 2-alternative forced-choice test:
What drives your decision when you are asked to make this choice? In the working memory literature, people often rely upon so-called "high-threshold" models, which say that you either remember the answer (memory is present in an all-or-none fashion), or else have no idea (memory is absent, also all-or-none). For example, Cowan's K is such a model. However, such models are widely considered unsuitable to understanding memory in the vast literature on recognition memory. For example, such models do not naturally explain why people are able to self-report a seemingly continuous measure of the strength of their own memory (as in ROC analysis; for more, see Wixted, 2019).
Thus, the dominant models of how people make responses in recognition memory focus to varying extents on signal detection theory. Signal detection theory in this context is very simple. It says that there is an underlying axis of how familiar something feels, which we might call "memory match signal" or simply "familiarity". Every stimulus evokes some value on this axis — but such signals are noisy. Even things you've never seen might feel slightly familiar sometimes. But a color you have seen will, on average, result in a higher familiarity signal than a color you didn't see. However, this won't be true on every trial. Since there is noise in the familiarity signals, sometimes the unseen color ( ) will happen to have more familiarity than the seen color ( ).
Here's a simple simulation where the memory for the seen item is relatively strong — with a boost of 2 tick marks on average relative to the unseen item. Try simulating trials and see how familiar we expect each item to seem on each trial, and how often the unseen item "wins" the competition to feel most familiar:
In this context, we've simulated a strong memory (+2 tick marks) and so the unseen color rarely 'wins' the competition. But this is very dependent on the distance, on average, between the seen and unseen familiarity values — which is what determines the memory strength. Try changing this memory strength of the previously seen item ( ) with the buttons here and then sampling again:
Notice that if you weaken the memory all the way, so there is no added familiarity to the seen color, then both are equally likely to seem most familiar. And conversely, if you strengthen the memory enough, only the previously seen color ever wins. But in between there is a large range of memory strengths where noise plays a large role in performance.
Let's try it again, but this time notice not only which color "wins", but also how familiar the winning memory is. This is how subjectively confident we would expect a participant to feel when choosing that color. Again, there is a role for noise here: The winning signal tends to have higher familiarity when the memory is stronger — but because of noise, this is not always true. In addition, particularly with relatively weak underlying memory strength, signal detection predicts that people sometimes have high familiarity, and thus high confidence, even when the winning color is the unseen color.
Confidence: 5/5
For example, here is an example of a trial where people express relatively high confidence — but they are incorrect about the color:
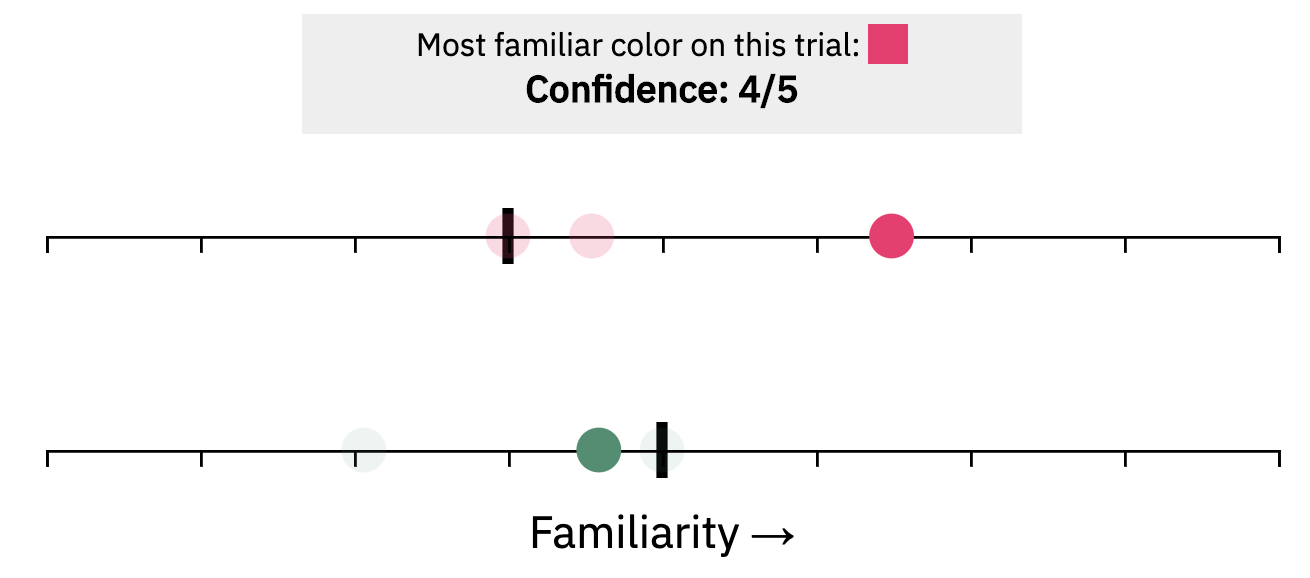
Notice that this kind of trial — high confidence errors — are fundamentally incompatible with high threshold models, since in such models people only make errors because they are guessing (a low confidence state). If guessing is the cause of errors, people should not be certain they are correct when they are in fact incorrect. But signal detection — which argues that noise in familiarity signals is genuinely felt as a memory — requires such trials to exist (1). The same concept applies to signal detection as a theory of perception, rather than memory. For example, when your brain is judging whether your cell phone is vibrating in your back pocket, your cortex is listening to noisy perceptual signals from your sensory neurons. These noisy signals sometimes genuinely result in high confidence false sensations: we've all experienced that we really do feel our phone vibrate in our pocket, even when it didn't really do so. Signal detection theory makes the exact same claim about familiarity in memory, which also arises from a noisy process.
How can we measure the underlying memory strength of an item? To measure memory strength in the context of signal detection, we need to make some labels for this axis. Because this familiarity axis is just in people's mind, we don't really know the units. So we define the units in terms of how far apart seen items are from unseen items — how much boost the studied item got compared to an unstudied item, which is something we can measure from people's performance. If they are one standard deviation apart, we say memory strength is d'=1. If they are 3 standard deviations apart, we say d'=3. The first simulation above had d'=2, so the underlying distribution of familiarity signals across trials looked like this:
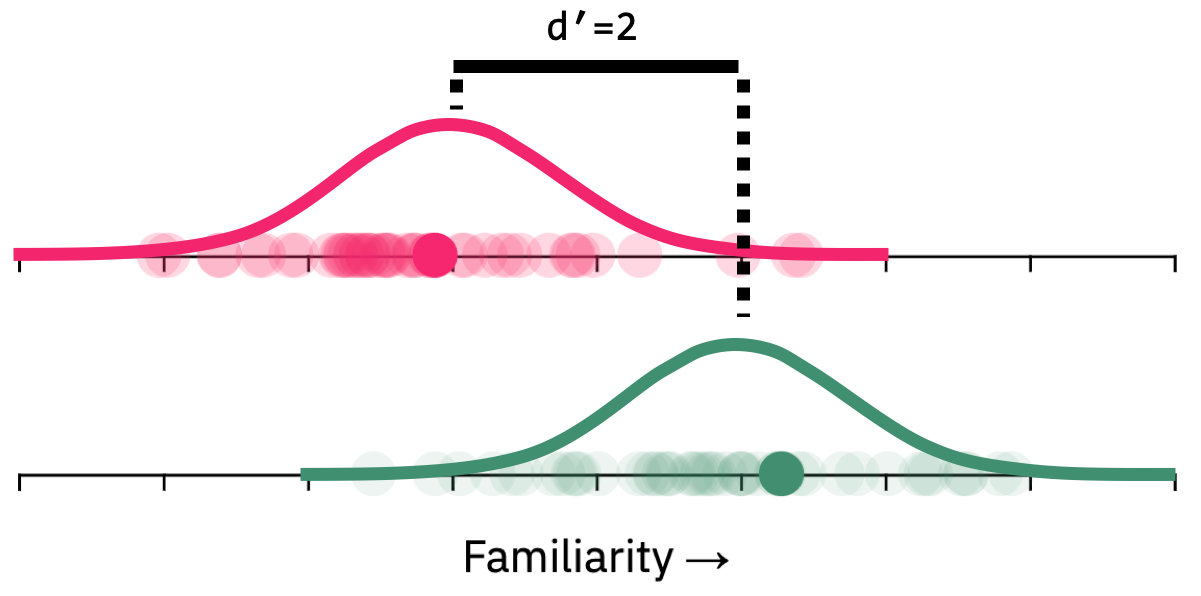
In our visualizations, this d' value is just how many 'tick marks' apart the two distributions are, since the noise in our sampling process has a standard deviation of 1 tick mark.
Those are the basics of signal detection theory with a 2-alternative forced-choice memory test for color. You see a color, which boosts the familiarity for that color by some amount (d'); then, through a noisy signal detection process, when tested you choose whichever color has a larger familiarity signal on that trial (the winner of the 'competition'!) — and which color this is varies quite a bit because noise is added to both familiarity values.
The Target Confusability Competition (TCC) model
The core insight of the Target Confusability Competition (TCC) — the "target confusability" part — is best explained by considering a very simple extension of this model to a 4-alternative forced-choice. In particular, imagine we've again asked you to remember this color: . Only this time, after some amount of delay, we ask you to say which of four colors you've seen in a 4-alternative forced-choice test:
How can we think about this? Of course, it is possible to simply extend the signal detection model described above to this 4-AFC case by saying that all 3 unseen colors have no added familiarity, and the seen color has familiarity added to it relative to all of them (e.g., d'=2). Then, on each trial, each of the 4 choices generates a familiarity value, and participants choose the one with maximum familiarity. In fact, this is how such n-AFC tasks are usually modeled in signal detection frameworks (e.g., in MacMillan and Creelman, 2005, the standard guide to signal detection theory). In this case, that means the familiarity values would look like this, on average across trials:
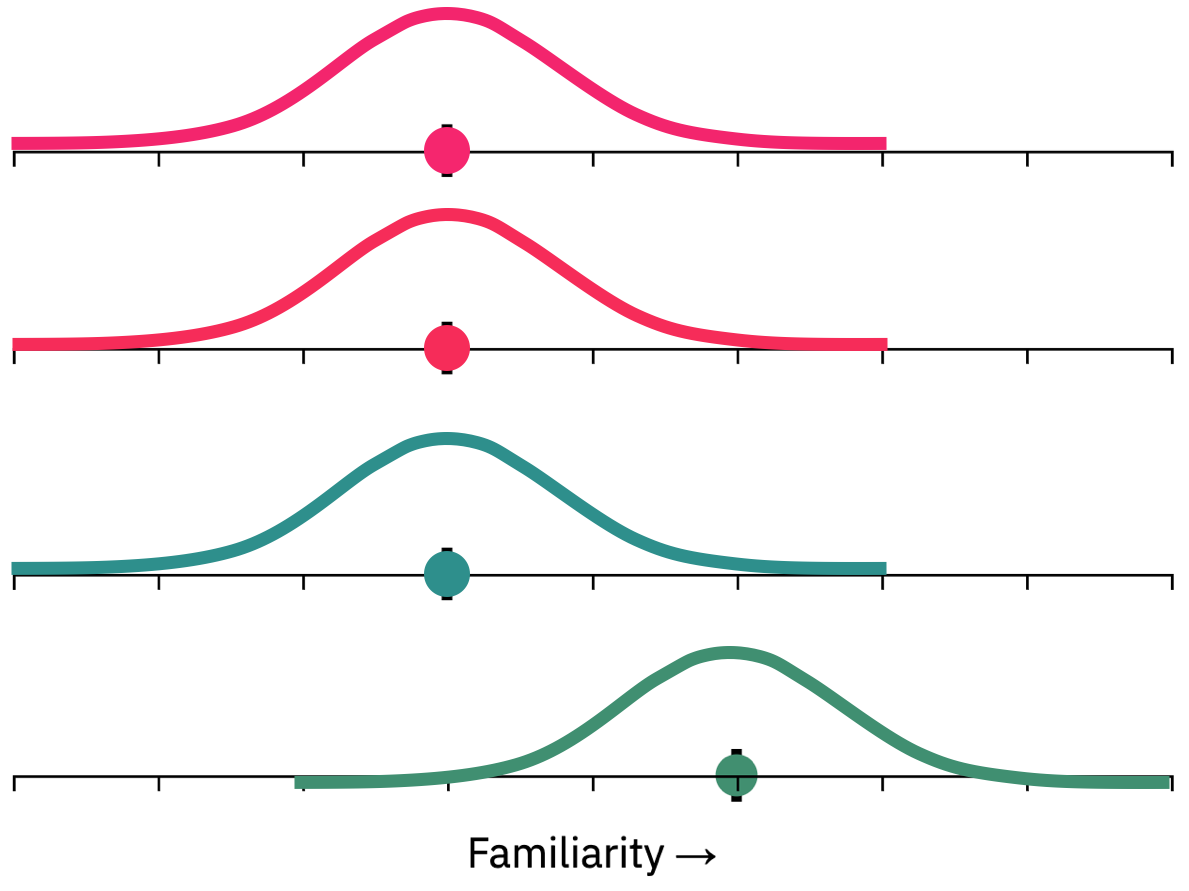
But notice that this makes an a priori absurd prediction — it suggests that people are equally likely to falsely choose Option 1 as they are to falsely choose Option 3, since both have the same familiarity distribution. Surely this cannot be the case, since Option 3 is so much more similar to the seen color? How confusable an item is with the target must play a role in memory performance.
If you believe that the only reasonable prediction is that people would choose Option 3 more than Option 1 or Option 2, then you believe in the Target Confusability Competition (TCC) model. In fact, the core insight of TCC is simply that the added familiarity an item gets is based on its psychophysical similarity to the seen color — thus, if any of your test options are very similar to the studied color, these colors will have added familiarity as well. In all other respects, TCC is simply the standard n-AFC model of signal detection. Here's TCC's take on the 4-AFC above, with Option 3 — the unseen item that is similar to the seen item — having somewhat boosted familiarity:
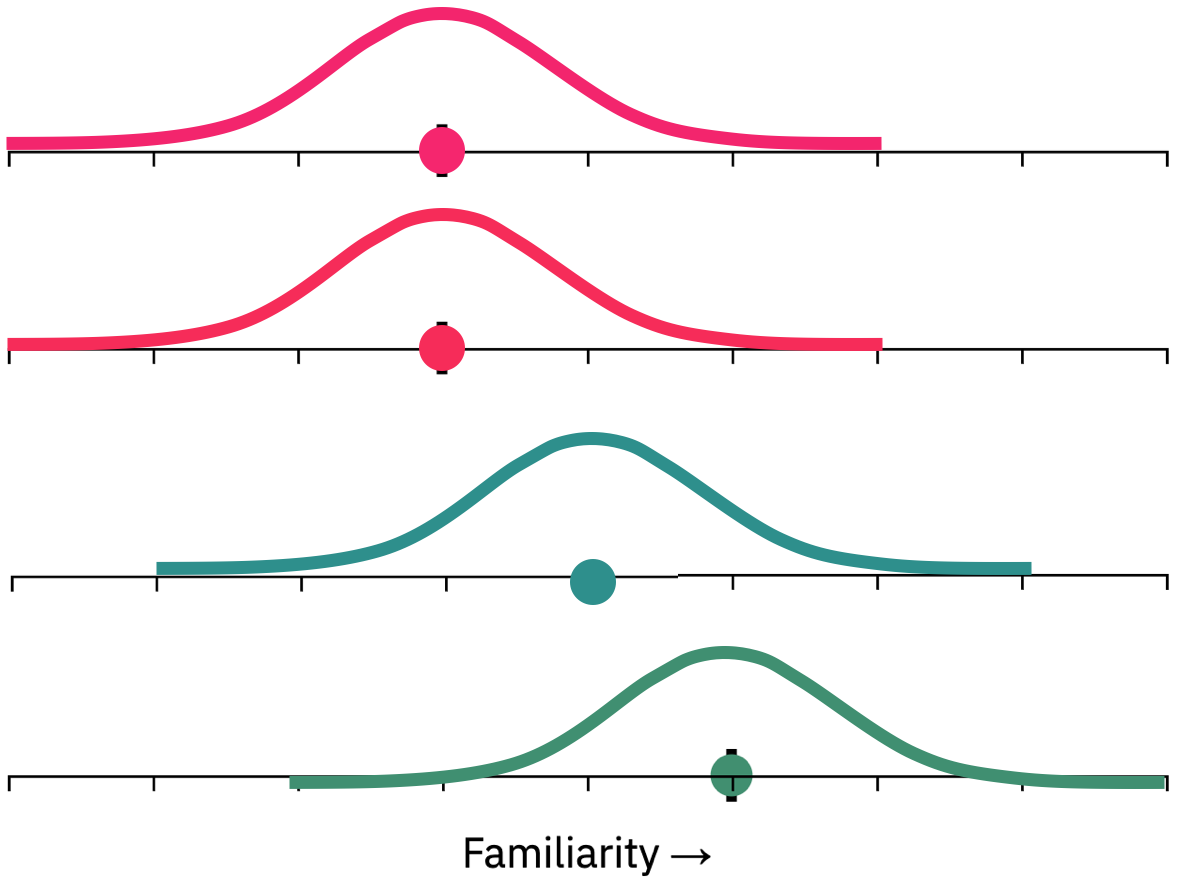
Naturally, this added familiarity makes people more likely to choose this color. To see exactly how much, let's make another simulation. This time, we'll "rotate" the familiarity axis so that more familiar is up, rather than more familiar being right. And we'll keep track of how often each of the 4 colors "wins" the competition.
Try simulating a few hundred trials. Now make memory strength maximal and simulate another set of trials. Notice the non-linearity: when memory strength is high, only the similar color or the correct answer ever wins; but when memory is weak, all of the colors become similarly likely to win the competition to be most familiar.
Even in this very simple situation, then, we can see the hallmark of so-called "mixture" models that are common in visual working memory. It is generally found that when memory is weak, people choose all dissimilar colors equally often, but when memory is strong, they never choose these colors. Mixture models claim this is evidence of a distinct 'guess state' in memory, where people frequently have no information at all about what they saw (a kind of high-threshold model, like mentioned above). Yet it is clear from even this 4-AFC situation that no such assumption needs to be made: instead, since there is a non-linearity that arises from people choosing their strongest familiarity signal, even very simple models can produce this kind of distribution.
To see this even more clearly, let's scale up that example to a
12-alternative forced-choice memory situation, with 12 colors chosen
from a 'color wheel':
 . In particular, imagine we've again asked you to remember this color:
. Only this time, after some
amount of delay, we ask you to say which of these
12 colors you've seen — a 12-AFC:
. In particular, imagine we've again asked you to remember this color:
. Only this time, after some
amount of delay, we ask you to say which of these
12 colors you've seen — a 12-AFC:
We can visualize this just the same way as before. In particular, we take the previously seen color and boost its familiarity by d'. We also boost memory for similar colors somewhat as well. But colors that are not similar to the seen color do not have their familiarity boosted at all. What happens when we simulate from this model?
Once again, we find this critical non-linearity. If you simulate several hundred trials, you'll find that when memory is strong, only very similar colors to the previously seen color have any hope of winning the competition:
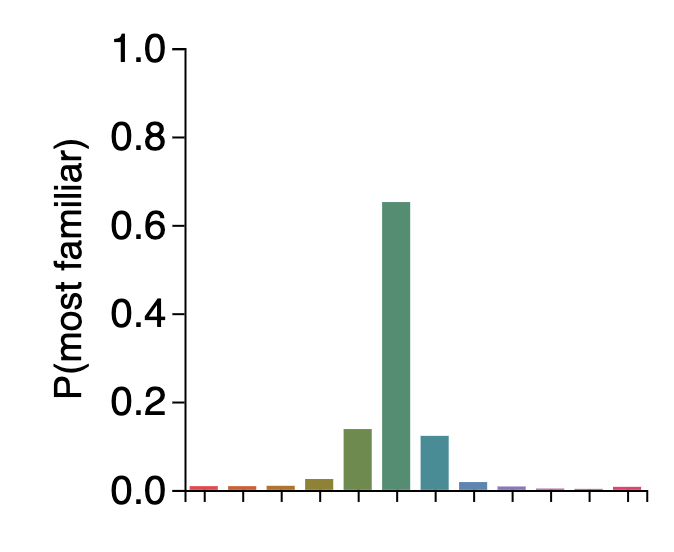
But when memory is weak, all of the colors can plausibly win — and all very dissimilar colors are about equally likely to win, since they have all not had their familiarity boosted at all. This results in a long, fat tail of errors, without any need for a 'mixture' or for distinct 'guess states':
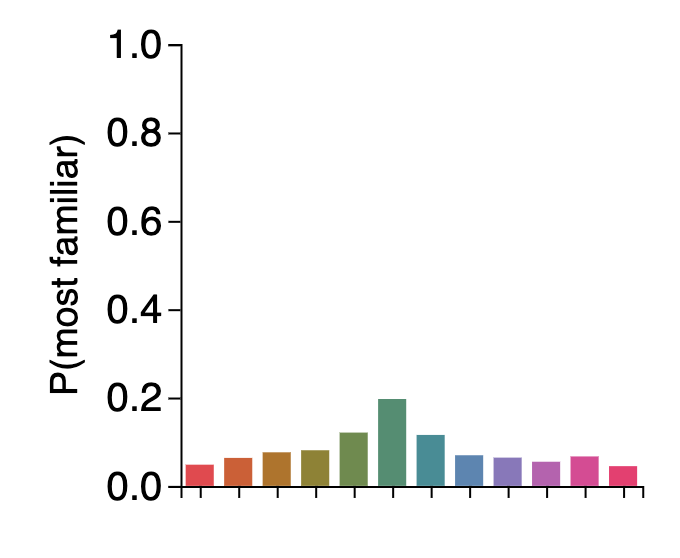
This is all the result of the exact same signal detection model we started off with for 2-AFC, with just one added idea: that seeing an item doesn't just boost familiarity for that item, but also for very similar colors.
The only thing needed to make this a complete model of memory — with no parameters at all other than memory strength — is to formalize the similarity function. How similar must a color be to the previously-seen-color to get added familiarity? How does this added familiarity fall off in color space or in other feature spaces?
So far, we've just been assuming a straightforward, approximately exponential fall-off of familiarity. This almost has to be approximately true, because memory confusability and similarity as well as generalization have long been known to follow an approximately exponential function of distance in psychologically uniform spaces (as CIELAB color space is, at least approximately). The exponential-like fall off in similarity can also be thought of as arising from simple measures of population overlap in color neurons, where far apart colors share almost no overlapping neurons, but nearby colors overlap substantially in which neurons code for them — also leading to an the exponential-like function (consistent, for example, with the proposal in this Paul Bays preprint on BioRxiv).
However, we don't really have to understand the origin of this similarity function — instead, we can also measure this similarity function empirically in a purely perceptual task (see Schurgin, Wixted and Brady, 2020, Nature Human Behaviour). In fact, even just showing people pairs of colors and getting Likert-scale ratings of similarity works just fine. A wide variety of ways of assessing similarity, in fact, all give functions like this:
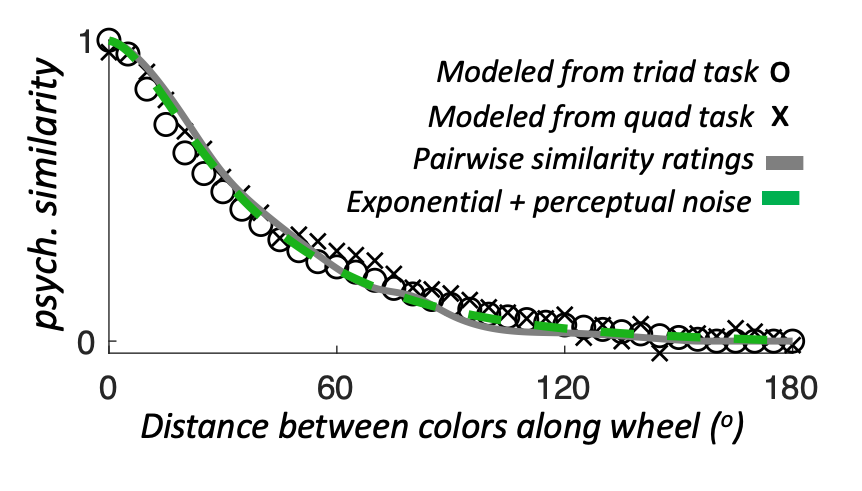
These functions looks like an exponential fall-off in similarity with distance in feature space, but with one added wrinkle: they look a bit flat near zero because for very nearby colors, there are additional confusions that arise from being unable to tell the colors apart at all (this too was previously known). Broadly, this similarity function just indicates with data something very intuitive: red is
more similar to pink than green , but red is not really any more similar to
blue than to green . This is true even though red is actually much closer to blue than green on the color
wheel (see:
), but anything that far apart on the color wheel is all considered by
our visual system to be just about maximally dissimilar (e.g., there is a large non-linearity in similarity).
The "Triad" task used in the Schurgin et al. paper nicely demonstrates this in a perceptual task, where your goal is to judge which of the bottom two items (left or right) is closer in color space to the top item (the target). In the left example, this is trivially easy; and in the right one, it is very hard. Yet in both of these examples, the two colors on the bottom (left vs. right) are exactly 30 degrees apart on the color wheel — demonstrating this large non-linearity in similarity.
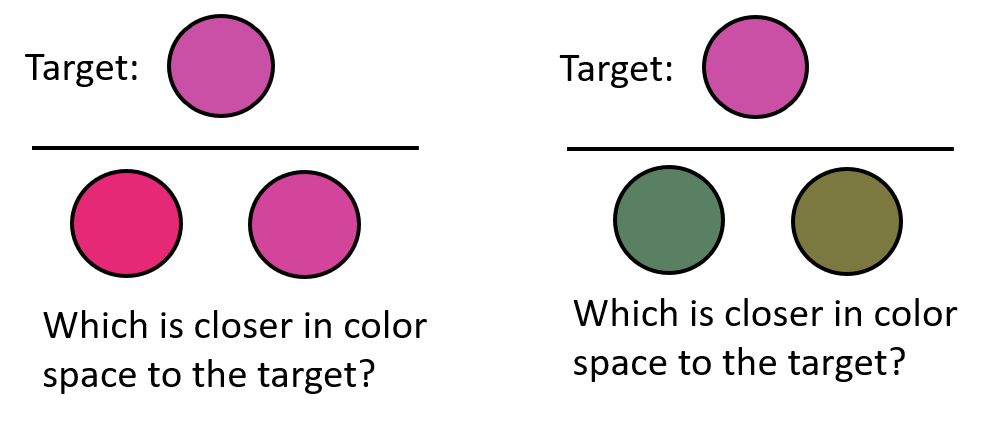
This task allows us to nicely measure the similarity function in an objective task. Most importantly, this function seems to be relatively fixed across participants — everyone agrees similarity is non-linear, and this non-linearity appears to be basically identical for everybody. In the TCC model it is also completely fixed across different values of memory strength, since familiarity spreading across color space always works the same way regardless of how much noise is subsequently added or how strong the memory is. Thus, this fixed similarity function in TCC does not play the same role that memory "precision" does in other models — previous conceptions of "precision" change with memory strength and across participants, but similarity in TCC is completely fixed across all participants and all memory strengths. It is simply a perceptual property of the stimulus space. The need for psychophysical similarity measurements in TCC is best thought of as the answer to a simple question: "how can we hope to understand memory errors without first understanding what things are perceptually confusable?" — TCC says, "we can't!".
Ok: we've now completely explained TCC. TCC is simply signal detection theory, but with the added 'twist' that similiar items get added familiarity — how well a color competes to win the 'competition' is determined by how 'confusable' it is with the 'target' color. Note that we've completely explained TCC, yet haven't even mentioned "continuous report" — the most common working memory task, where people are asked to choose from an entire color wheel what color they had previously seen:
|
Remember this color: |
... |
What color did you see?
|
Notice that in the TCC framework, there is nothing special about such "continuous report" tasks. In fact, the 12-AFC task proposed above, or even the 2-AFC task, both are totally sufficient if you wish to measure d', the underlying memory strength(2). Although note that continuous report tasks may be better if you are interested in attraction/repulsion or location noise/'swap' errors, which can be obscured in 2-AFC. However, these play little role in the tasks we model in the Schurgin et al. paper. Of course, it is also the case that if people only ever do 2-AFC, with maximally distinct colors, they may encode the colors differently -- in our task we prevent this by intermixing trials that require different kinds of responses. In the Schurgin, Wixted, Brady paper, we show just this: giving people a 2-AFC task (e.g, did you see red or green?) is sufficient to completely predict their entire pattern of errors in continuous report. In the TCC view, the only thing that happens when you switch to continuous report measures is that you introduce a lot more very similar color choices, further complicating the response distributions. Nevertheless, TCC has no problem explaining these distributions using the exact same model we used in the 12-AFC task, but now with e.g., 360 colors:
This model provides good fits to the data from both working memory and long-term memory color report tasks, and is purely a direct generalization of signal detection theory. For example, here is the distribution of how far off from the correct answer this model predicts people will be at different values of d' (the error, in degrees along the color wheel):
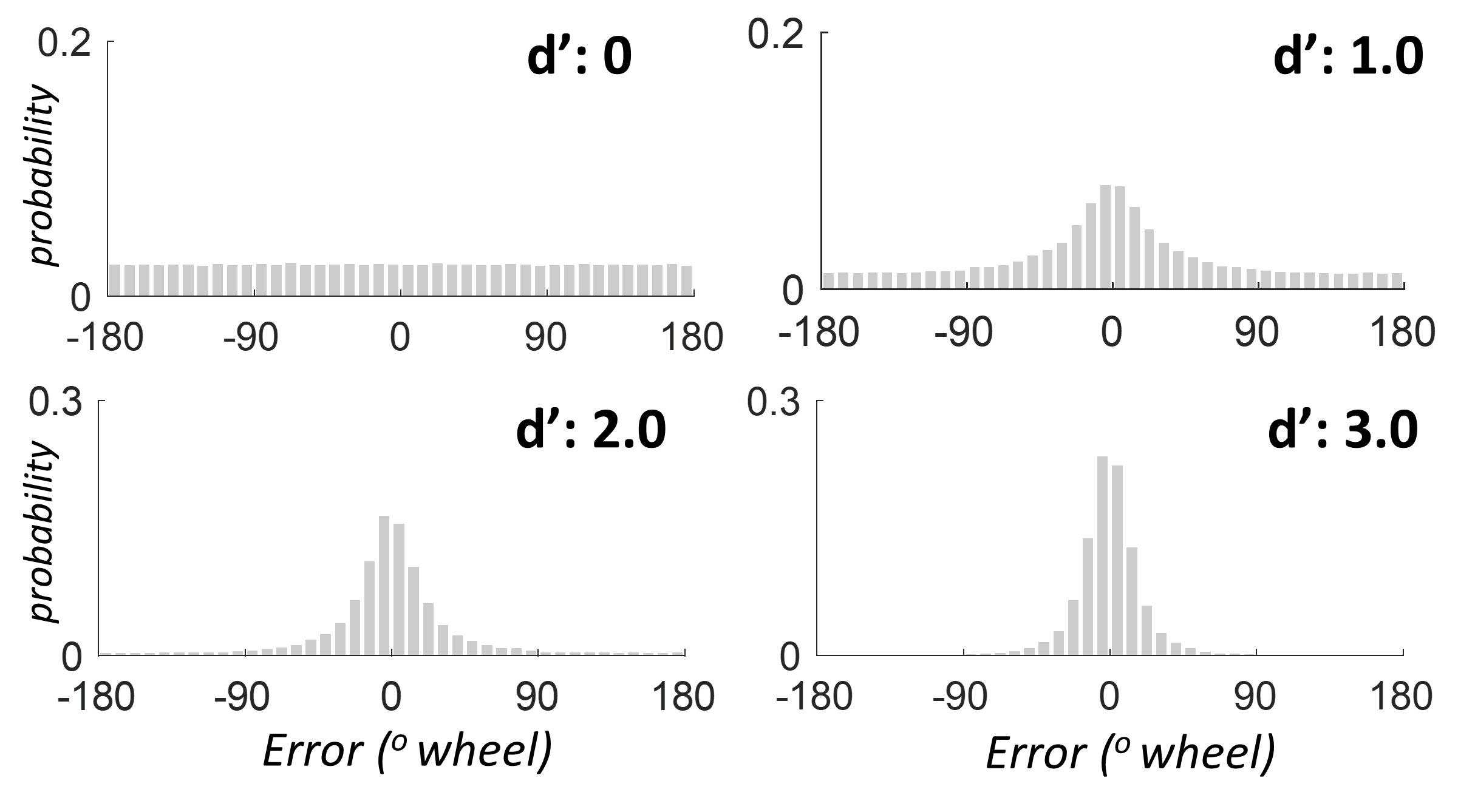
We can see how accurately this matches real data by converting the model predictions to the blue line, and showing the actual data from real participants as gray bars. Here is the data when people are asked to hold in mind 1, 3, 6 or 8 colors at once, and then probed on their memory for one of the items using continuous report. Notice that it is perfectly fit by TCC — with just one parameter, how strong the memory is:
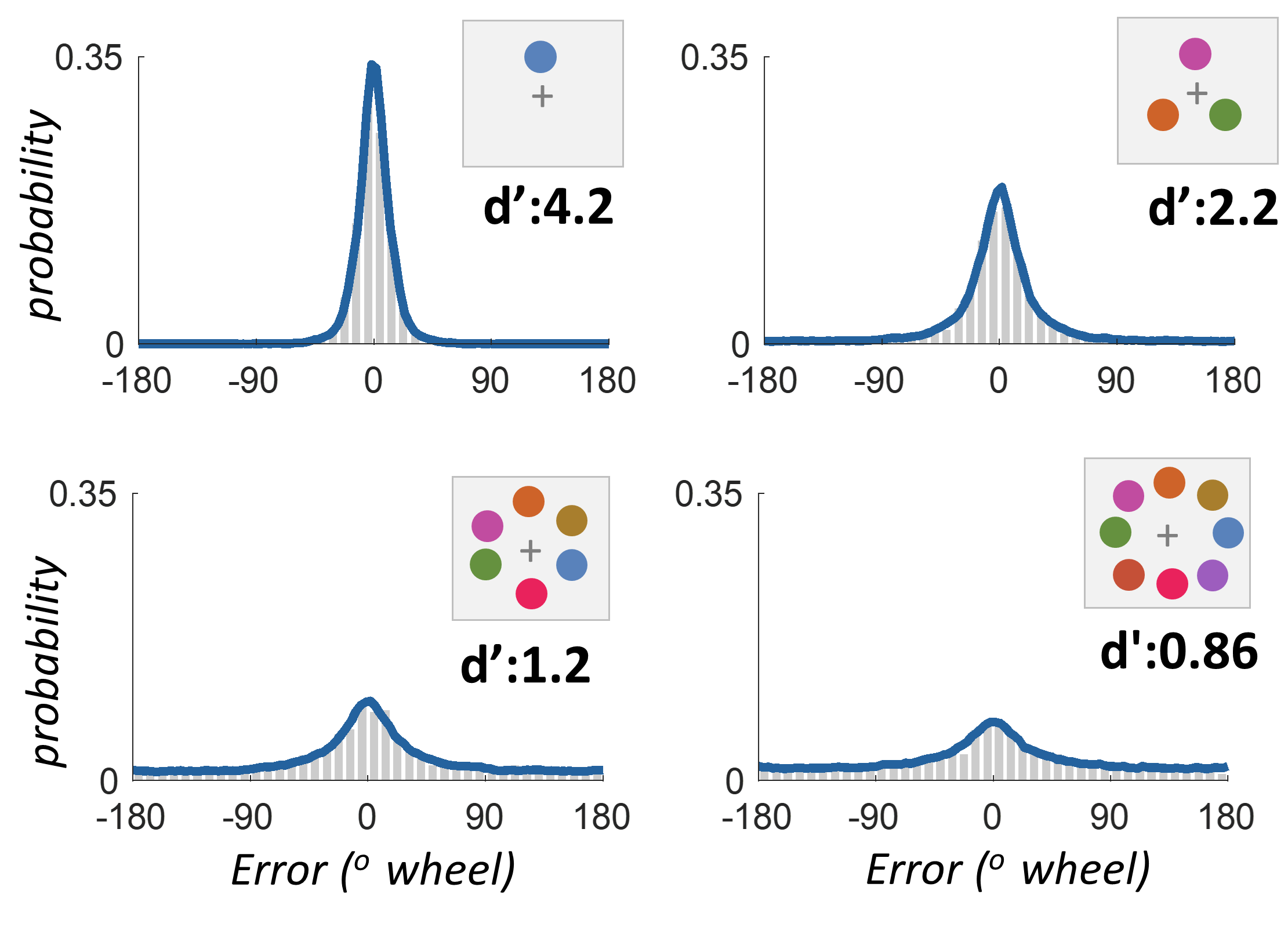
Notice that these distributions appear to have separate long, fat tails. This is the reason 'mixture models', have, quite reasonably, been conceived of as reflecting separate states, of either unrepresented items or very poorly represented items. Yet this data is well fit by this very simple generalization of signal detection theory without any need for multiple processes or different kinds of representations.
In fact, this model can be further refined ever so slightly to make it even more accurate, without changing the excellent fit to the data: In many ways, assuming that the noise added to color N and color N+1 is totally independent, as in the above simulation, is quite odd. Instead, we'd probably assume that nearby colors would have smoothly varying familiarity — after all, the memory signals for them depend on almost exactly the same underlying neurons. In many ways, TCC starts with signal detection theory, but ends up being quite similar to models of population coding in neurons. That is, it has noise as a central component, and conceives of memory as not being a "point representation" ("I think the item at this location was blue") but an entire population of familiarity signals ("my memory for this item is a sense of how familar all of the colors feel at this location"). Thus, in the 'final' version of TCC, we smooth the noise that is added to adjacent colors. We use data from a perceptual matching task — rather than a free parameter — to choose how much to smooth the noise, though TCC's predictions are basically unaffected by this smoothing. Ultimately, the TCC model of continuous report ends up looking like this:
Thus, in TCC terms, we think about memory like this: First, when the trial starts, nothing is encoded in memory. Then the memory is encoded — the amount of encoding strength can vary (e.g., it might be lower if encoding time is short, or multiple items are present). Then, during the delay, noise accumulates. The amount of noise can also vary (e.g., it might be higher if there are more items being maintained or if the delay is longer). Then, whenever memory is probed, people report the color with the strongest familiarity. Their accuracy allows us to infer d', which is the signal-to-noise ratio — the signal detection measure of memory strength.
One last point is worth returning to briefly: the role of confidence. In TCC, as in all signal detection models, people's subjective confidence is a reflection of how strong the familiarity signal is. Therefore TCC — with no modifications — makes several important predictions about confidence. One is that, as in all signal detection models, there must be high confidence errors, even in continuous report. 'Mixture models' claim the long tail of errors in continuous report arises from a separate 'guessing state'. If this is true, such guessing states should not give rise to high confidence, and the long tail should be completely absent in the highest confidence responses. By contrast, if this long tail arises from a signal detection process, as in TCC, it will still be present to some extent even at the highest confidence level. We, along with many others, find the signal detection prediction is true. When memory strength is low, then error distributions at even the highest confidence levels inevitably have a long tail of far away errors:
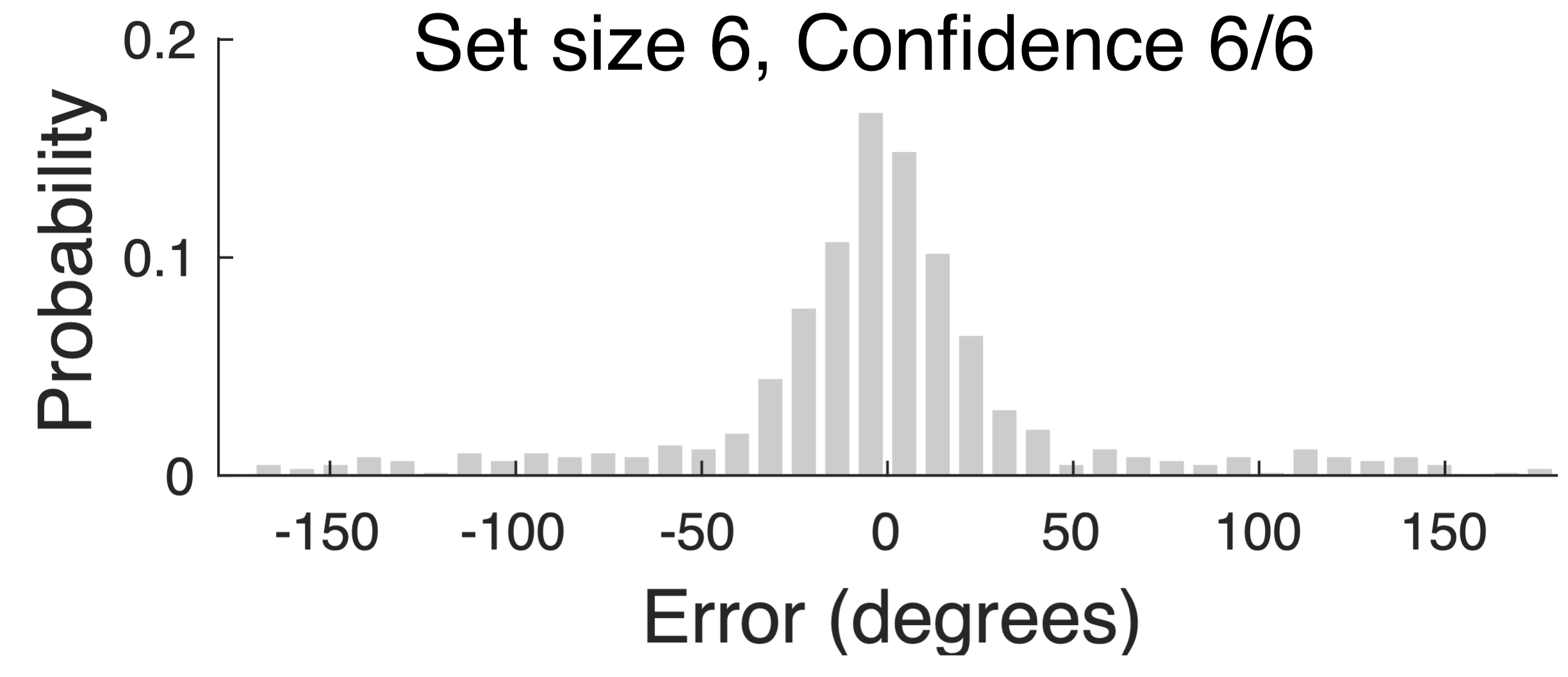
Another confidence prediction TCC makes that is worth pointing out is in the opposite direction: the role of very low confidence. People often find the idea of a separate 'guessing state' appealing because they subjectively believe they are guessing, particularly in hard conditions (e.g., set size 8 working memory tasks). However, this subjective feeling of guessing is quite distinct from the existence of an objective 'guessing state'. Signal detection, and TCC by extension, clearly and straightforwardly predict this subjective impression of guessing: TCC agrees with intuition that we often feel like we have "no idea" (e.g., confidence 0/5). This arises in TCC from trials where none of the familiarity signals are strong, which occurs frequently at high set sizes. TCC simply rejects the idea that this is occuring because we literally have no information — instead, TCC naturally accounts for the frequency of this subjective feeling by noisy variation in familiarity signals.
Altogether, then, this is TCC: by combining psychophysical scaling of similarity with signal detection theory, we make a straightforward model of both visual working and visual long-term memory. Combining these two extremely well-established concepts together results in a simple model, with no need for 'mixtures' or 'guess states' or 'very low precision items'. And this model allows us to make novel predictions and explain memory performance in a very straightforward way.